
Abstract
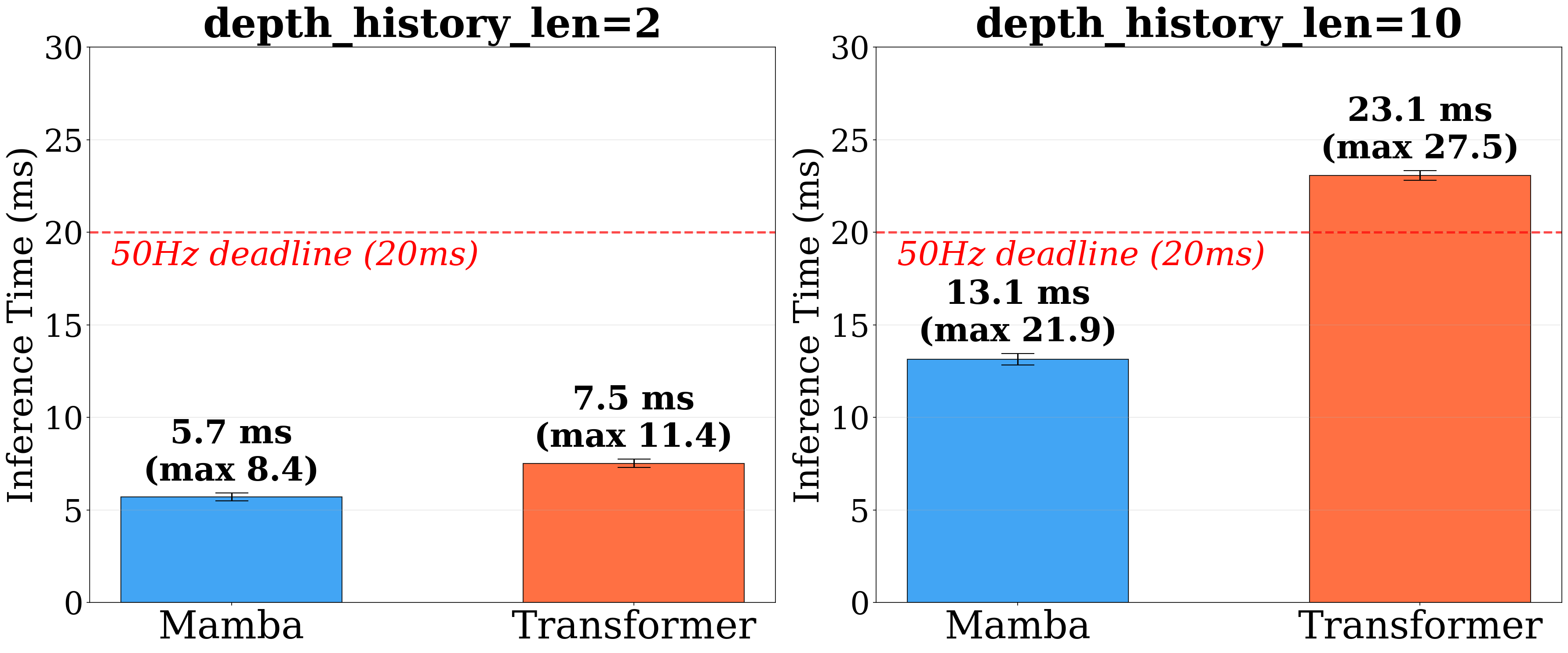
Extreme legged parkour demands rapid terrain assessment and precise foot placement under highly dynamic conditions. While recent learning-based systems achieve impressive agility, they remain fundamentally fragile to perceptual degradation, where even brief visual noise or latency can cause catastrophic failure. To overcome this, we propose Robust Extreme Agility Learning (REAL), an end-to-end framework for reliable parkour under sensory corruption. Instead of relying on perfectly clean perception, REAL tightly couples vision, proprioceptive history, and temporal memory. We distill a cross-modal teacher policy into a deployable student equipped with a FiLM-modulated Mamba backbone to actively filter visual noise and build short-term terrain memory. Furthermore, a physics-guided Bayesian state estimator enforces rigid-body consistency during high-impact maneuvers. Validated on a Unitree Go2 quadruped, REAL successfully traverses extreme obstacles even with a 1-meter visual blind zone, while strictly satisfying real-time control constraints with a bounded 13.1 ms inference time.
Motivation
Extreme legged parkour seeks to endow quadrupedal robots with the ability to execute highly agile maneuvers across discontinuous, cluttered, and dynamically challenging terrains. Such tasks require rapid terrain assessment, gait transitions, precise foot placement, and continuous balance regulation — all under strict timing and torque constraints.
Despite recent advances, existing methods remain highly vulnerable to perceptual degradation. Extreme parkour entails impacts, rapid rotations, flight phases, and motion blur, where even brief visual corruption can cause catastrophic failure. Most approaches treat perception as a direct feedforward input to control, without modeling observation uncertainty, exploiting temporal memory, or enforcing physics consistency.
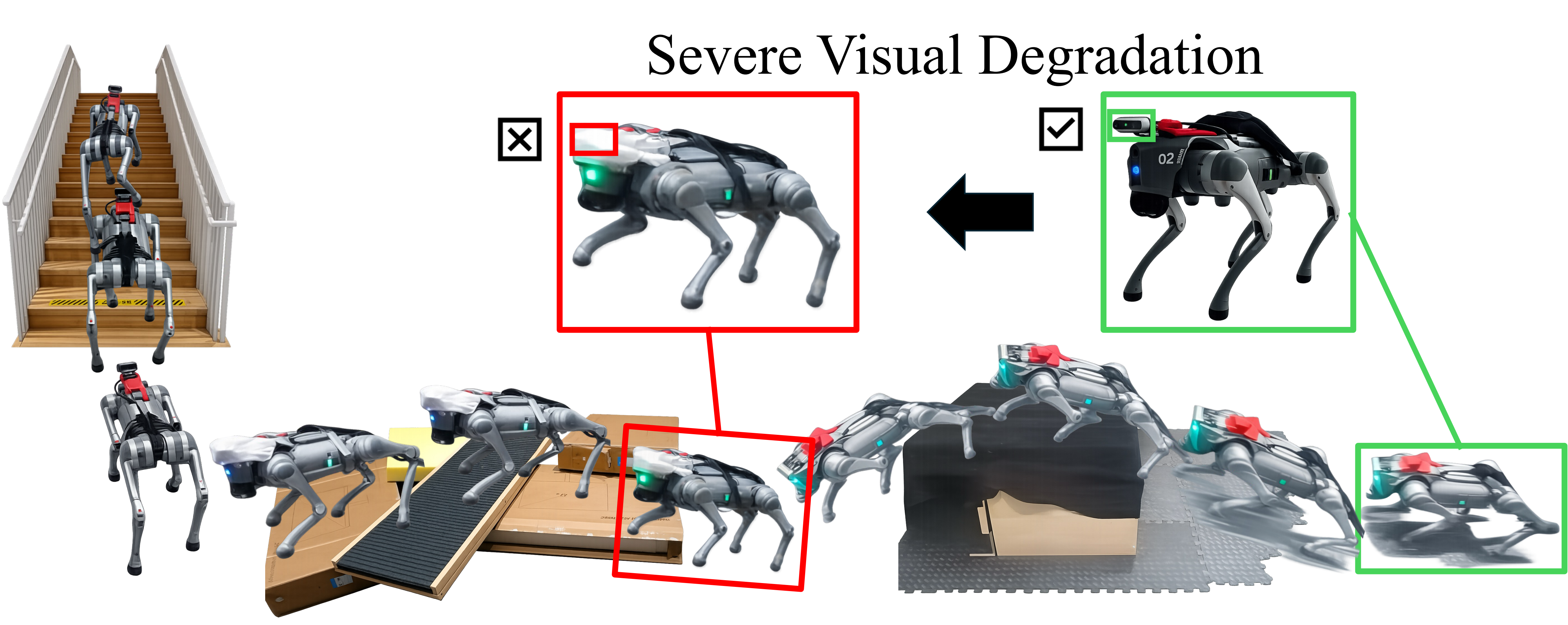
Method
REAL is an end-to-end policy learning framework that tightly integrates vision, proprioception, and temporal memory within a unified spatio-temporal architecture. The framework adopts a two-stage training paradigm:
- Stage 1 — Privileged Teacher Policy Learning: A privileged teacher policy is trained via reinforcement learning (RL) in simulation with access to proprioceptive observations, terrain scan points, and additional privileged information.
- Stage 2 — Student Policy Distillation: The teacher policy is distilled into a deployable student policy that operates using only onboard depth sensing and proprioception.
Spatio-Temporal Policy Learning
The privileged teacher leverages a cross-modal attention mechanism to establish structured proprioception–terrain reasoning. Terrain features are retrieved and aggregated conditioned on the robot’s proprioceptive state via:
The student policy integrates two core modules:
- FiLM (Feature-wise Linear Modulation): Proprioception dynamically modulates visual features to suppress unreliable signals during impacts or rapid rotations:
- Mamba Temporal Backbone: Provides efficient sequence modeling with linear-time inference complexity, maintaining long-horizon terrain memory when exteroceptive input degrades:
Physics-Guided Filtering
An uncertainty-aware neural velocity predictor is fused with rigid-body dynamics through an Extended Kalman Filter (EKF). The learned predictor provides adaptive uncertainty estimates, while the dynamics model enforces physical constraints.
The Kalman gain adapts automatically: when the neural predictor reports high uncertainty, correction magnitude decreases. Confident predictions exert stronger influence, ensuring stable velocity tracking under impacts, slippage, and partial sensor degradation.
Consistency-Aware Loss Gating
An adaptive gating coefficient dynamically balances behavioral cloning (BC) and reinforcement learning (RL):
When action discrepancy is large, imitation learning dominates for stability. As the student aligns with the teacher, the objective shifts toward RL for robustness.
Experiments
Extreme Terrain Traversability

REAL achieves a high overall success rate, effectively doubling the performance of prior vision-only baselines across hurdles, steps, and gaps.
| Method | Hurdles SR | Steps SR | Gaps SR | Overall SR | Overall MXD | MEV ↓ |
|---|---|---|---|---|---|---|
| Extreme Parkour | 0.18 | 0.14 | 0.10 | 0.16 | 0.21 | 34.24 |
| RPL | 0.05 | 0.04 | 0.03 | 0.04 | 0.10 | 1.56 |
| SoloParkour | 0.42 | 0.49 | 0.36 | 0.39 | 0.34 | 96.93 |
| REAL (Ours) | 0.82 | 0.94 | 0.28 | 0.78 | 0.45 | 18.41 |
Robustness Against Perceptual Degradation
Under severe visual degradation conditions — frame drops, Gaussian noise, and spatial FoV occlusion — REAL demonstrates exceptional resilience:
| Method | Nominal SR | Frame Drop SR | Gaussian Noise SR | FoV Occlusion SR |
|---|---|---|---|---|
| Extreme Parkour | 0.16 | 0.16 (↓0.00) | 0.11 (↓0.05) | 0.13 (↓0.03) |
| RPL | 0.04 | 0.01 (↓0.04) | 0.01 (↓0.03) | 0.01 (↓0.03) |
| SoloParkour | 0.39 | 0.20 (↓0.19) | 0.37 (↓0.03) | 0.41 (↑0.02) |
| REAL (Ours) | 0.78 | 0.61 (↓0.17) | 0.51 (↓0.27) | 0.72 (↓0.06) |
Blind-Zone Maneuvers

With vision masked 1 m before obstacles, standard baselines suffer catastrophic forgetting and immediate failure. REAL leverages historical multi-modal data to implicitly track the terrain:
| Method | SR ↑ | MXD ↑ | MEV ↓ | Time ↓ | Coll. ↓ |
|---|---|---|---|---|---|
| Extreme Parkour | 0.11 | 0.20 | 44.03 | 0.15 | 0.29 |
| RPL | 0.00 | 0.03 | 0.35 | 0.00 | 0.04 |
| SoloParkour | 0.36 | 0.34 | 103.50 | 0.06 | 0.09 |
| REAL (Ours) | 0.55 | 0.39 | 24.84 | 0.03 | 0.08 |
Real-World Deployment

REAL achieves robust zero-shot sim-to-real transfer, completing diverse real-world obstacle courses with only onboard perception and computing. The policy is deployed via a custom C++ framework, with inference optimized using ONNX.
Blind Zone Video Comparison
Baseline Results - Visual Degradation Test
BASELINE METHODS
Flat Terrain
Fails immediately without visual input
Hurdle Terrain
Severe performance degradation
Step Terrain
Struggles without visual guidance
REAL Results - Robust Blind Navigation
OUR METHOD (REAL)
Flat Terrain
Maintains stable locomotion
Hurdle Terrain
Successfully navigates obstacles
Step Terrain
Robust performance with physics guidance
Real-Time Performance
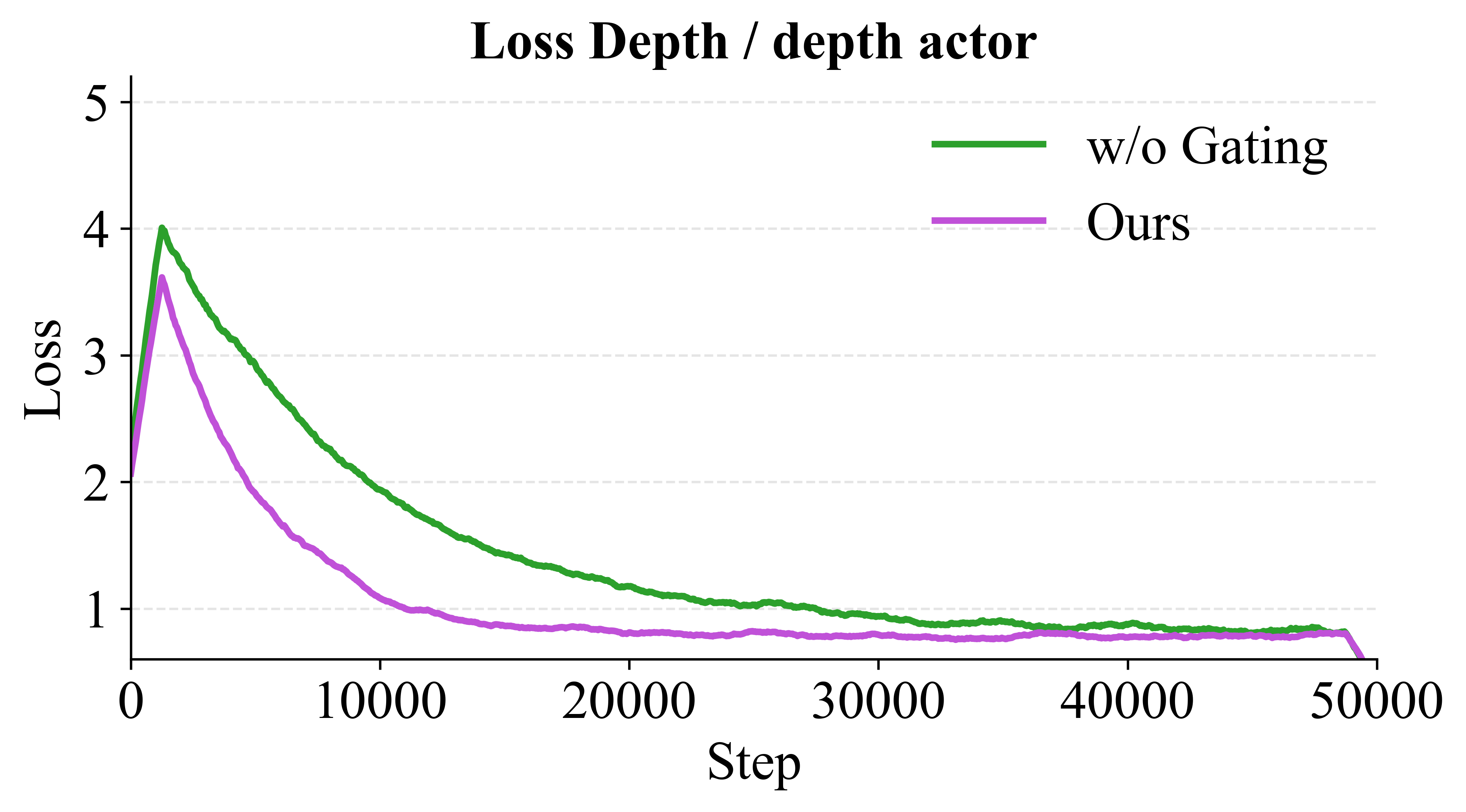
Ablation Study
Component Ablation
| Method | SR ↑ | MXD ↑ | MEV ↓ | Time ↓ | Coll. ↓ |
|---|---|---|---|---|---|
| REAL (Ours) | 0.78 | 0.45 | 18.41 | 0.02 | 0.06 |
| REAL (w/ MLP Est.) | 0.73 | 0.43 | 19.34 | 0.02 | 0.06 |
| REAL (w/o FiLM) | 0.44 | 0.51 | 93.43 | 0.28 | 0.06 |
| REAL (w/o Mamba) | 0.51 | 0.47 | 89.96 | 0.26 | 0.05 |
- Without Mamba: Success rate plummets and Mean Edge Violations increase nearly fivefold, confirming that Mamba’s long-term sequence modeling is essential for tracking historical terrain features.
- Without FiLM: Success rate drops to 44%. Without dynamic sensory gating, the policy treats noisy visual inputs as ground truth, leading to frequent collisions.
Velocity Estimation
| Estimator Architecture | RMSE ↓ |
|---|---|
| MLP (Baseline) | 0.52 |
| MLP + EKF | 0.40 |
| 1D ResNet (Single frame) | 0.33 |
| 1D ResNet (10 frames) | 0.28 |
| 1D ResNet + EKF (Ours) | 0.23 |
Training Convergence
BibTeX Citation
@article{real2026, title = {REAL: Robust Extreme Agility via Spatio-Temporal Policy Learning and Physics-Guided Filtering}, author = {Jialong Liu, Dehan Shen, Yanbo Wen, Zeyu Jiang and Changhao Chen}, year = {2026}}